

Understanding Compiler Design

Every one of us has used a compiler once in our programming journey or must have read about it. Ever thought about how a compiler works?
Today I will be discussing the design structure of a compiler.
A code basically has to pass through a different number of levels to get itself converted from high-level language to assembly language, and these are all hidden in a compiler.
Here is a basic diagram of a compiler :
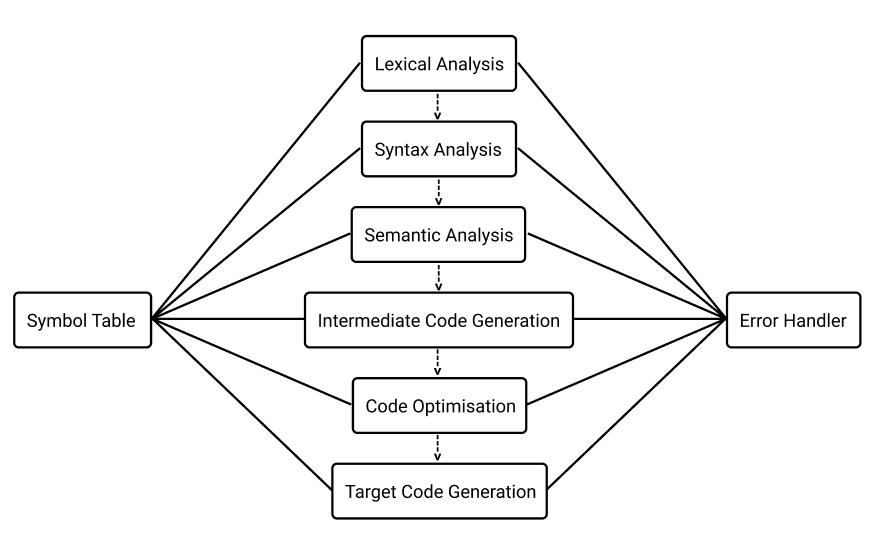
As we can see a compiler consists of a total of 6 different levels, where the first four are grouped together and are called frontend, and the bottom two are grouped and called backend.
The frontend part checks for any kind of errors in the code like syntax, grammar, or lexical errors whereas the backend part simplifies and generates the program by grouping the code snippets.
The Internal Processes in brief.
When we write code in any language and compile it, the first thing a compiler does is to check for any kind of errors in the code for which it passes through the frontend or analytic part.
Lexical Analysis
When a high-level language code is passed through lexical analysis it generates a stream of tokens.
But before lexical analysis, an optional stage happens that works only when a pre-processor is present in the code like #include <iostream.h> in C++, called preprocessor itself.
The task of a preprocessor is to filter out a stream of characters by removing the header files and then passing it to the lexical analysis. (A stream of characters is nothing but just the keyboard characters we type in the code: int a = 23; or printf(" Hello World! ");)
Now coming back to lexical analysis, we were talking about tokens. So, what is a token?

let's take a small code a = 10;.
Here a, =, 10, ; are all tokens. So, the total number of tokens here is 5.
So basically a token is the important part of a code.
Why I said important?
Because things like comments and other characters such as white space or newline or tabs are not considered as tokens.
And then these tokens are passed in the symbol table.
The role of the symbol table is to maintain a record of the properties of tokens or variables such as their type, size, scope, etc. The symbol table is connected to all the stages in the compiler as we can see in the diagram for future use.
After converting all the code to tokens, it is sent to the syntax analysis department.
Syntax Analysis
When the code comes here, it is checked that if a code is syntactically correct or not. A parser is used here and the output that comes is called a parse tree as it comes in the form of a tree as shown.
(If you have studied Automata theory, you must have read about Pushdown Automata, the practical application of PDA is here in creating the parse tree)
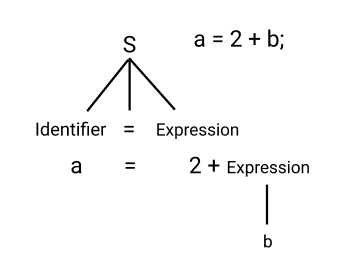
The syntactical errors in the code are produced in this stage.
Semantic Analysis
In Semantic Analysis, the analyzer checks the parse tree and finds semantic errors. Note that this part doesn't care about the syntax but checks whether the value of the variable is as per the type declared or the limit of a particular data type is not exceeded or whether variables are declared properly or not.
Something like int a = "hello"; here the analyzer will produce an error as the type of the variable is different from the type of value.
Intermediate Code Generator
This part is the middle man between frontend and backend, it generates a code that can be understood by the backend and hence it generates a machine-independent code (independent of OS).
It creates a 3-address code.
A 3-address code is created by dividing the code statement into 3 a variable statement which means that there can only be maximum of 3 variables present in one code statement, if there is 4 or 5 then it is divided into 2 3 lines of code.
a = b + c * d; // 4 variable statement. So, it will be broken down to 3 variables.
x = c * d;
a = b + x;
This 3-addressed code is then sent to the next level i.e. optimization of code
Code Optimisation
From here the backend part begins and code optimization is the first stage of the backend. As the name suggests, this part optimizes the code. There is not much to say about it as you all know what is optimisation.
For a machine, a plus (+) sign is much easier to process than a multiplication (*) sign, hence a code like:
x = 4 * y
// can be converted to
x = y + y + y + y
// or
z = y + y;
x = z + z;
Code generation
Here the code generator takes an optimized version of the intermediate code and links it with the target machine language. It translates the intermediate code into a sequence of re-locatable machine code. The machine code generated works the same way the intermediate code would do.
Like the Symbol Table, there is an error handler, that is linked to all the phases which is responsible for handling the errors detected by the frontend.
And at last, the code is converted to the assembly code or machine code.




